
Anthropic představil dva nové a dlouho očekávané modely své řady Claude a to Opus 4 a Sonnet 4. Lze konstatovat významné pokroky v oblasti kódování, zatímco jiné aspekty vykazují nerovnoměrný vývoj. Shrnuto: jde o povinný upgrade LLM v momentu, kdy se všichni chlubí novými modely, ale žádný průlomový model mimo programování to není. Přesto jej budete používat rádi.
Tiskovou zprávu a firemní rozcestník na další detaily najdete zde
Technické specifikace a hybridní architektura
Oba modely představují evoluci směrem k hybridní reasoning architektuře, která nabízí dva odlišné provozní režimy. Standardní režim zajišťuje rychlé odpovědi pro běžné dotazy, zatímco extended thinking mode umožňuje modelům věnovat více času komplexnějším problémům vyžadujícím hlubší analýzu. Tato dualita představuje praktický kompromis mezi rychlostí a kvalitou odpovědí.
Zajímavým aspektem je schopnost modelů přecházet mezi uvažováním a používáním nástrojů během jedné interakce. Modely mohou například během analýzy problému provést webové vyhledávání, zpracovat získané informace a pokračovat v uvažování s novými daty. Tato funkcionalita výrazně rozšiřuje praktické možnosti použití oproti statickým modelům předchozích generací. Něco podobného už máme v ChatGPT u o3, ale v modelech Anthropicu je to vítanou novinkou. Velkou přidanou hodnotou je, že Opus těchto angentů spouští klidně velké množství, takže pokud potřebujete prozkoumat řadu zdrojů a kriticky je vyhodnotit, Opus 4 je v tom podstatně výkonnější, než o3.
Výkonnostní analýza podle benchmarků
Kódování - průlomové výsledky
Oblast vývoje software představuje nejpozoruhodnější pokrok nové generace Claude modelů. V benchmark SWE-bench Verified, který testuje schopnost řešit reálné GitHub issues, dosahuje Claude Opus 4 úspěšnosti 79,4% a Sonnet 4 dokonce 80,2%. Tyto výsledky výrazně překonávají OpenAI o3 (69,1%) i GPT-4.1 (54,6%). Paradoxně se tak méně výkonný Sonnet 4 v této konkrétní oblasti jeví jako lepší volba než vlajková loď Opus 4, byl zjevně trénován především na programování, protože u něj se uplatní i jeho nízká cena oproti Opusu 4.
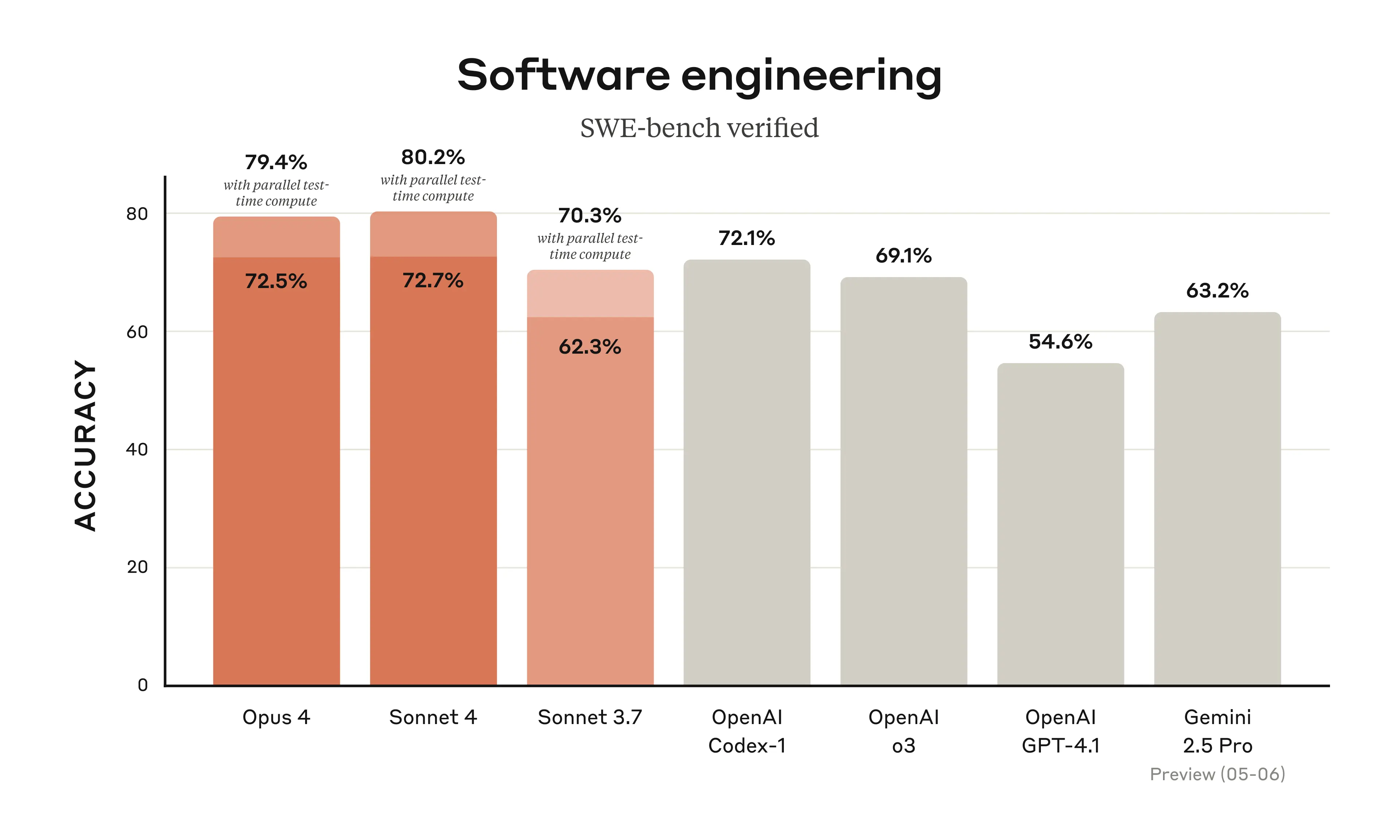
V oblasti agentického kódování - komplexnějších programátorských úloh vyžadujících autonomní práci - oba modely dosahují srovnatelných výsledků okolo 72-73%, což představuje podstatné zlepšení oproti Sonnet 3.7 (62,3%). Významný je také pokrok v úlohách terminálového kódování, kde Opus 4 dosahuje 43,2% úspěšnosti oproti 35,2% u předchozí generace.
Podle nezávislých recenzí od vývojářských nástrojů jako Replit a Cursor dokážou nové modely provádět “precizní změny napříč masivními codebase” a představují “to nejlepší pro vývojáře”. Claude Code, terminálové rozhraní pro programátory, je nyní obecně dostupné a umožňuje kontinuální práci na komplexních projektech po dobu hodin. Sám musím potvrdit, že schopnost Claude Code se Sonnet 4 se mi jeví jako výrazně lepší než u jeho předchůdce. Úlohy, které vysloveně nemám rád, jako napojování na databáze, u Sonnet 4 fungují o řád lépe. Například jsem jím odladil hodnocení článků na konci každého článku zde na serveru, můžete vyzkoušet…
Reasoning a analytické schopnosti
Výsledky v oblasti logického uvažování a analýzy jsou podstatně méně konzistentní. Zatímco ve středoškolské matematice (AIME 2024) dosahují modely výrazného zlepšení - Opus 4 na 75,5% oproti 54,8% u Sonnet 3.7 - jiné oblasti vykazují stagnaci nebo dokonce pokles.
V graduate-level reasoning (GPQA) Opus 4 dosahuje 79,6%, což je prakticky shodné se Sonnet 3.7 (78,2%), zatímco Sonnet 4 dokonce klesá na 75,4%. Podobně neuspokojivé jsou výsledky ve visual reasoning, kde všechny modely oscilují okolo 74-76% bez jasného trendu zlepšení.
Vícejazyčné schopnosti vykazují postupný pokrok - Opus 4 dosahuje 88,8% v MMMLU benchmark oproti 85,9% u předchozí generace, což naznačuje zlepšení v neanglofonním prostředí. Zde ale musím říct, že pro češtinu pozoruji významné zhoršení, do textů pronikají anglicismy nebo rovnou celé anglické sentences, což is bad. Teď to trochu paroduju, ale celý večer používám Opus a Sonnet 4 jako mentora pro mé psaní druhého dílu Flotily a je to hodně poznat. Schopnosti jsou lepší, vyjadřování v češtině je horší.

Praktické nasazení a ekonomické aspekty
Cenová struktura zůstává beze změny oproti předchozím generacím: Claude Opus 4 stojí 15 dolarů za milion vstupních tokenů a 75 dolarů za výstupní tokeny, zatímco Sonnet 4 je dostupný za 3 respektive 15 dolarů. Významnou novinkou je hodinové prompt caching, které snižuje náklady o 90% a latenci o 85% pro dlouhé, multi-step agent workflows s persistentním kontextem.
Nové Files API umožňuje nahrát dokumenty jednou a znovu je používat napříč sezeními, což je ideální pro datasety, analýzy a persistentní file-based workflows. Code execution tool poskytuje možnost spouštět Python kód přímo přes Anthropic API, což umožňuje kompletní data analysis, charting a document automation v jednom workflow.
Integrace s vývojářskými nástroji dosahuje nové úrovně - nativní podpora pro VS Code, JetBrains a GitHub umožňuje pracovat s Claude přímo v kontextu kódu. Místo “promptování” modelu s ním uživatelé skutečně spolupracují, přičemž editace se zobrazují inline a feedback probíhá v rámci kontextu.
Halucinace a věrohodnost výstupů
Problematika halucincí představuje stále výzvu pro všechny současné LLM modely. Z dostupných informací vyplývá, že nové Claude modely nezaznamenaly průlomové zlepšení v této oblasti. Modely stále vykazují tendenci k vytváření fakticky nesprávných informací, zejména v situacích, kdy se snaží zodpovědět dotazy mimo svou znalostní bázi.
Zajímavým aspektem je zavedení summarizace myšlenkových procesů u nejdelších thinking sekvencí pomocí menšího modelu. Tato funkce má potenciálně ambivalentní dopad na halucincae - zatímco může pomoci strukturovat komplexní uvažování, současně zavádí další vrstvu potenciální nepřesnosti prostřednictvím summarizačního modelu.
Extended thinking mode teoreticky poskytuje lepší možnosti pro self-correction a ověřování faktů během delšího uvažování, což by mohlo snížit frekvenci halucincí u komplexnějších dotazů. Praktické dopady této funkce však nejsou v dostupných materiálech detailně kvantifikovány.
Nové funkcionality a workflow integrace
Claude 4 generace přináší několik zásadních rozšíření funkcionalit. Model Control Protocol (MCP) connector umožňuje připojení k externím nástrojům jako Zapier nebo Asana bez nutnosti klientského kódu - stačí přidat URL a systém je funkční. Tato schopnost výrazně rozšiřuje možnosti automatizace a integrace do existujících workflow a je to příjemná změna proti dřívější editaci JSON souboru.
Schopnost používat nástroje během uvažování, jako je webové vyhledávání, otevírá možnosti pro více-agentní a více-nástrojové pracovní postupy, které skutečně škálují. Model může během analýzy problému autonomně vyhledávat informace, ověřovat fakta a aktualizovat své chápání situace.
Integrace s GitHubem se také citelně zlepšuje. Uživatelé mohou Claude označit v pull requestech, požádat o opravu CI issues nebo automaticky odpovídat na review. Tato funkcionalita transformuje Claude z pasivního nástroje na aktivního účastníka vývojového procesu.
Kritické zhodnocení a perspektivy
Claude 4 generace představuje výrazně nerovnoměrný pokrok napříč různými oblastmi schopností. Zatímco v kódování dosahují modely skvělých výsledků, v jiných klíčových oblastech jako reasoning a analytické schopnosti zůstává pokrok marginální nebo dokonce nenastal.
Nejvíce znepokojivá je stagnace v graduate-level reasoning, která naznačuje, že současný přístup k tréninku modelů možná dosahuje svých limitů v oblasti obecné inteligence. Zlepšení v kódování lze částečně připsat specializaci trénovacích dat a procesů na programátorské úkoly, což však nemusí být udržitelný přístup pro budoucí generace.
Graduate-level reasoning označuje schopnost logického uvažování a řešení problémů na úrovni vysokoškolského studia vyšších stupňů (magisterské a doktorské studium). V kontextu hodnocení AI modelů se jedná o komplexní analytické schopnosti.
Cenová dostupnost při zachování výkonu představuje pozitivní aspekt pro širší adopci, zejména v kontextu startupů a menších firem budujících AI-powered aplikace. Hodinové prompt caching a Files API výrazně snižují operační náklady pro komplexní agent workflows.
Integrace s development tools dosahuje nové úrovně sofistikace a praktičnosti, což může akcelerovat adopci AI asistentů ve vývojářských týmech. Přechod od “promptování” k “spolupráci” s modelem představuje významný posun v user experience.
Závěr
Claude 4 generace reprezentuje specialized breakthrough spíše než general intelligence advancement. Výrazné zlepšení v kódování a software engineeringu ustanovuje tyto modely jako nové standardy pro programátorské AI nástroje, zatímco stagnace v jiných oblastech odhaluje limity současných přístupů k tréninku LLM.
Pro praktické nasazení představují nové modely výrazné zlepšení pro vývojářské workflow, ale jejich dopad na obecné schopnosti AI zůstává omezený. Absence zlepšení v oblasti halucincí a nekonzistentní pokrok v reasoning naznačují, že cesta k obecné umělé inteligenci bude vyžadovat fundamentálně odlišné přístupy než pouhé škálování současných architektur.
Bude zajímavé sledovat, jak se s “třídesetinkovým” upgradem podaří Anthropicu vklínit mezi slušně rozjetý Google, který své novinky představil nedávno (zastavíme se u nich v newsletteru) a mezi OpenAI a jeho modely o3 a o4, zejména o4 se mělo zlepšit v kódování.
Osobně bych stále doporučoval používat Opus 4 pro zpracování, editaci textu (a pak ručně vychytat anglicismy) a Sonnet pro programování. Na každodenní úlohy s ponorem do tématu mě zatím nic nevymluvilo používání o3. Pro psaní jsem dlouho měl v češtině radši Claude, nový přístup k češtině mi nesedí a budu silně zvažovat, že přejdu k o3. Snad se ta čeština vyladí.
Musím také poznamenat, že výsledky pro “staré úlohy” nejsou o tolik lepší, aby to odůvodňovalo zásahy do zdrojového kódu, pokud už máte nějakou technologii rozeběhanou a odladěnou na starších modelech. Pokud by vám nestačil nový model, který je levnější, není dnes příliš mnoho dalších důvodů, proč na novější model přecházet…