Souhrn
xAI Grok 4.20 představuje nový přístup k modelům umělé inteligence prostřednictvím nativní rady čtyř specializovaných agentů, kteří spolupracují paralelně a zvyšují kvalitu výstupů v oblastech jako uvažování, faktická kontrola a inženýrské úlohy. Článek porovnává tento systém s podobnými vývoji u Anthropic Claude 4.6, OpenAI GPT-5.3 Codex, Google Gemini 3.1 a čínskými modely, jako jsou DeepSeek nebo Kimi. Klíčovým prvkem je přechod od jediných modelů k víceagentním strukturám, které snižují halucinace a zvyšují efektivitu bez výrazného navýšení nákladů.
Klíčové body
- Grok 4.20: Rada agentů (Grok jako koordinátor/syntetizátor, Harper pro výzkum a fakta zakotvená v datech z platformy X, Benjamin pro logiku, matematiku a kód, Lucas pro kreativitu a rovnováhu); paralelní běh s interní debatou a RL-optimalizovanou orchestrací.
- Výhody: Zlepšení hloubky uvažování, kontroly faktů, detekce slepých míst a open-ended engineering s overheadem 1,5–2,5× oproti jednoprstupovému módu.
- Porovnání: Claude 4.6 exceluje v týmových agentech pro kódování, GPT-5.3 Codex je self-improving s test-time compute, Gemini zdůrazňuje tool-use, čínské modely nabízejí levné agent swarms.
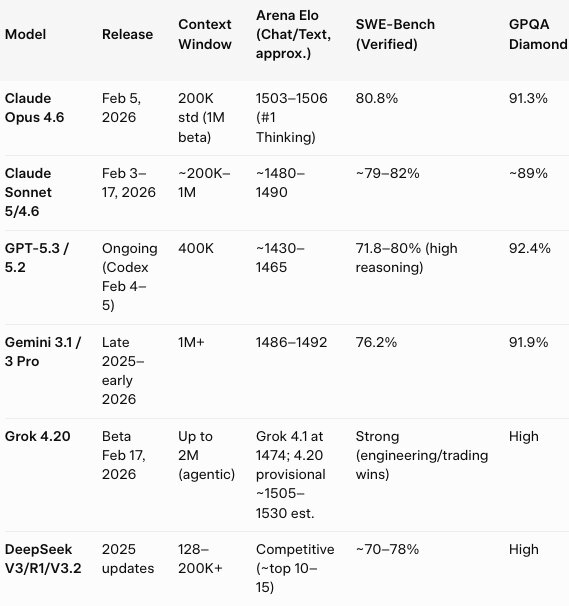
- Náklady: Claude Opus 4.6: 5 $/15 $/mil. tokenů input/output; GPT-5.3: 1,75 $/14 $/mil.; Gemini 3.1: 2 $/12 $/mil.
Podrobnosti
Model xAI Grok 4.20, vyvinutý společností xAI Elona Muska, zavádí nativní čtyřagenta strukturu, kde každý agent má specifickou roli: Grok koordinuje a syntetizuje výstupy, Harper se zaměřuje na výzkum, fakta a zakotvení v reálných datech z platformy X (dříve Twitter), Benjamin řeší logické úlohy, matematiku a generování kódu, zatímco Lucas přináší kreativitu a udržuje rovnováhu v debatě. Agenti běží paralelně na sdílených vahách modelu a KV cache, což umožňuje efektivní sdílení kontextu bez nutnosti opakovaného výpočtu. Proces zahrnuje strukturované kola interní debaty, optimalizované pomocí reinforcement learning (RL), což vede k výraznému poklesu halucinací díky křížové verifikaci.
Tento systém dosahuje velkých zlepšení v hloubce uvažování, kontrole faktů, detekci slepých míst a řešení otevřených inženýrských problémů, přičemž náklady rostou jen o 1,5–2,5× oproti standardnímu jednoprstupovému průchodu. Například v reálném čase je ideální pro trading nebo komplexní engineering, kde tradiční modely selhávají kvůli nedostatečné hloubce.
Anthropic Claude 4.6 série představuje nativní Agent Teams v preview verzi pro kódování (Claude Code), kde paralelní sub-agenti koordinují dlouhodobé úlohy jako práce s repozitáři kódu. OpenAI GPT-5.3 Codex je vysoce agentický a self-improving – dokáže ladit vlastní trénink a nasazení – s důrazem na test-time compute v o-series stylu a tool-based orchestraci. Google Gemini 3.1 silně podporuje tool-use a agentické workflow, ale méně explicitní multi-agent debatu. Čínské modely jako DeepSeek, Kimi K2.5 nebo Qwen experimentují s agent swarms a multi-view planningem, což je cenově atraktivní, ale méně vyspělé než Grok nebo Claude.
API ceny odrážejí premium postavení: Claude Opus 4.6 stojí 5 $/input a 25 $/output na milion tokenů (pro kontexty nad 200K), Sonnet levněji kolem 3 $/15 $; GPT-5.3 1,75 $/14 $; Gemini 3.1 Pro 2 $/12 $ pro menší kontexty.
Proč je to důležité
Přechod k paralelním víceagentním systémům představuje klíčový krok k systémové inteligenci, kde specializace agentů nahrazuje limity jediných velkých modelů. Pro uživatele to znamená spolehlivější AI pro složité úlohy jako kódování, analýzu dat nebo rozhodování v reálném čase, s nižším rizikem chyb. V průmyslu tlačí na cenové války – čínské modely snižují ceny – a urychluje pokrok k AGI. Grok 4.20 vyniká unikátní integrací dat z X a always-on radou, zatímco Claude dominuje v enterprise kódování díky bezpečnosti. GPT buduje agenty, Gemini exceluje v multimodálních úkolech. Tento trend zvyšuje efektivitu bez explodujících výpočetních nákladů a mění AI z nástroje na tým expertů.
Zdroj: 📰 Next Big Future