
O francouzské společnosti Mistral AI se v poslední době mluvilo hlavně kvůli spekulacím, zda si ji nechce koupit Apple jako urychlení svého AI vývoje. To by byla pochvala pro evropský vývoj AI a zároveň rána, protože by to velký AI model dotáhlo pod křídla americké firmy. Mistral ale nově vydal Voxtral - svůj první otevřený model zaměřený na zpracování zvuku, tedy především přepisu nahrávek do textu.
Model je dostupný ve dvou variantách (24B a 3B parametrů), překonává současné standardy včetně OpenAI Whisper large-v3 a ElevenLabs Scribe, přičemž jeho API stojí přibližně polovinu oproti konkurentům. Pojďme se na něj podívat podrobněji.
Technické specifikace a možnosti
Voxtral je postaven na základě jazykového modelu Mistral Small 3.1 a rozšiřuje jeho textové schopnosti o komplexní zpracování zvuku. Model je licencován pod Apache 2.0, což umožňuje široké komerční využití bez omezení. Lze si jej také stáhnout a provozovat na lokálním počítači.
Větší varianta Voxtral s 24 miliardami parametrů je určena pro produkční nasazení, zatímco Voxtral Mini se 3 miliardami parametrů cílí na lokální spuštění a okrajová zařízení. Oba modely pracují s kontextem až 32 000 tokenů, což umožňuje zpracování audia dlouhého až 30 minut pro transkripci nebo 40 minut pro porozumění obsahu. Delší obsahy se řeší tak, že se rozdělí na kratší soubory.
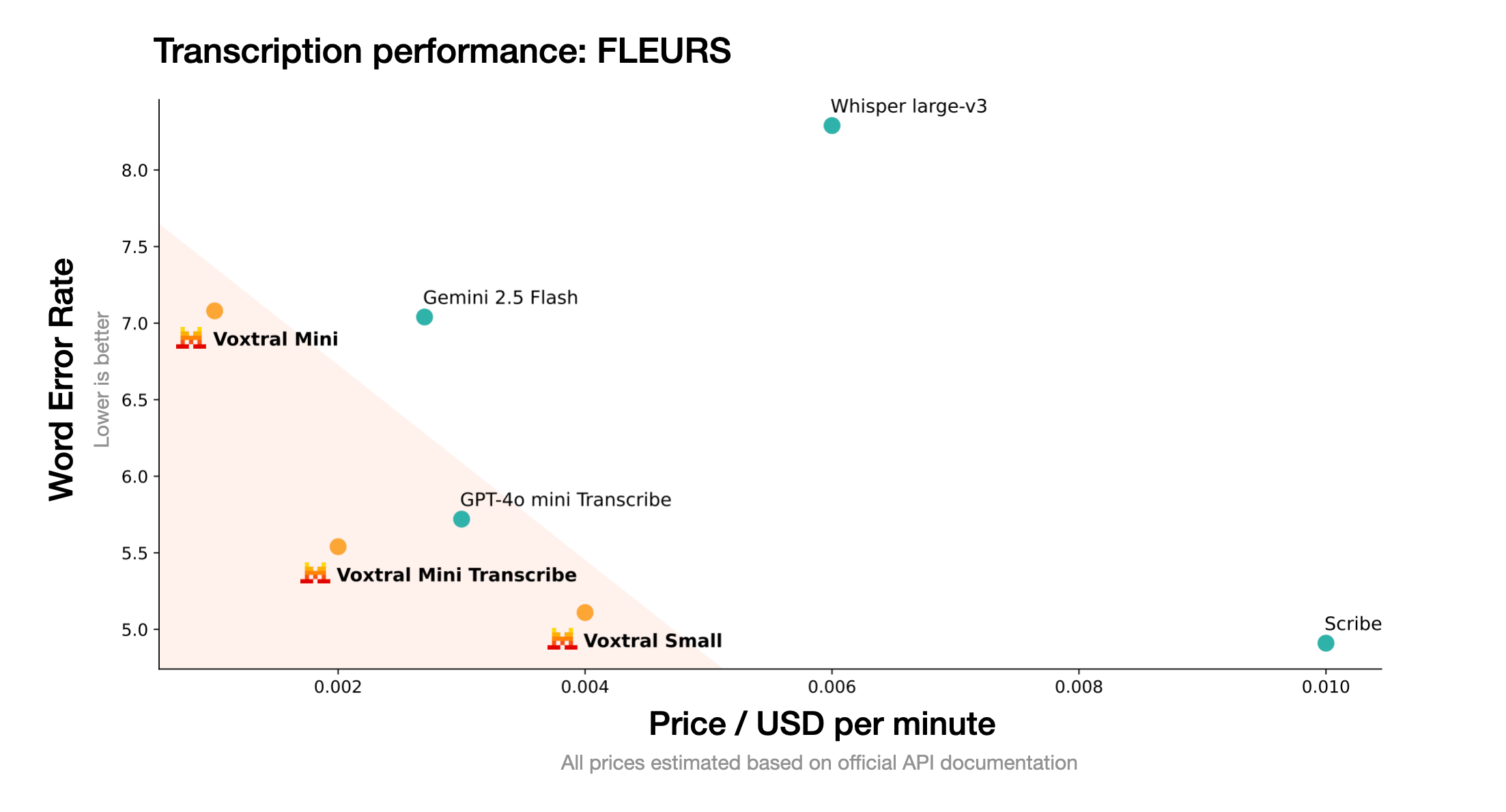
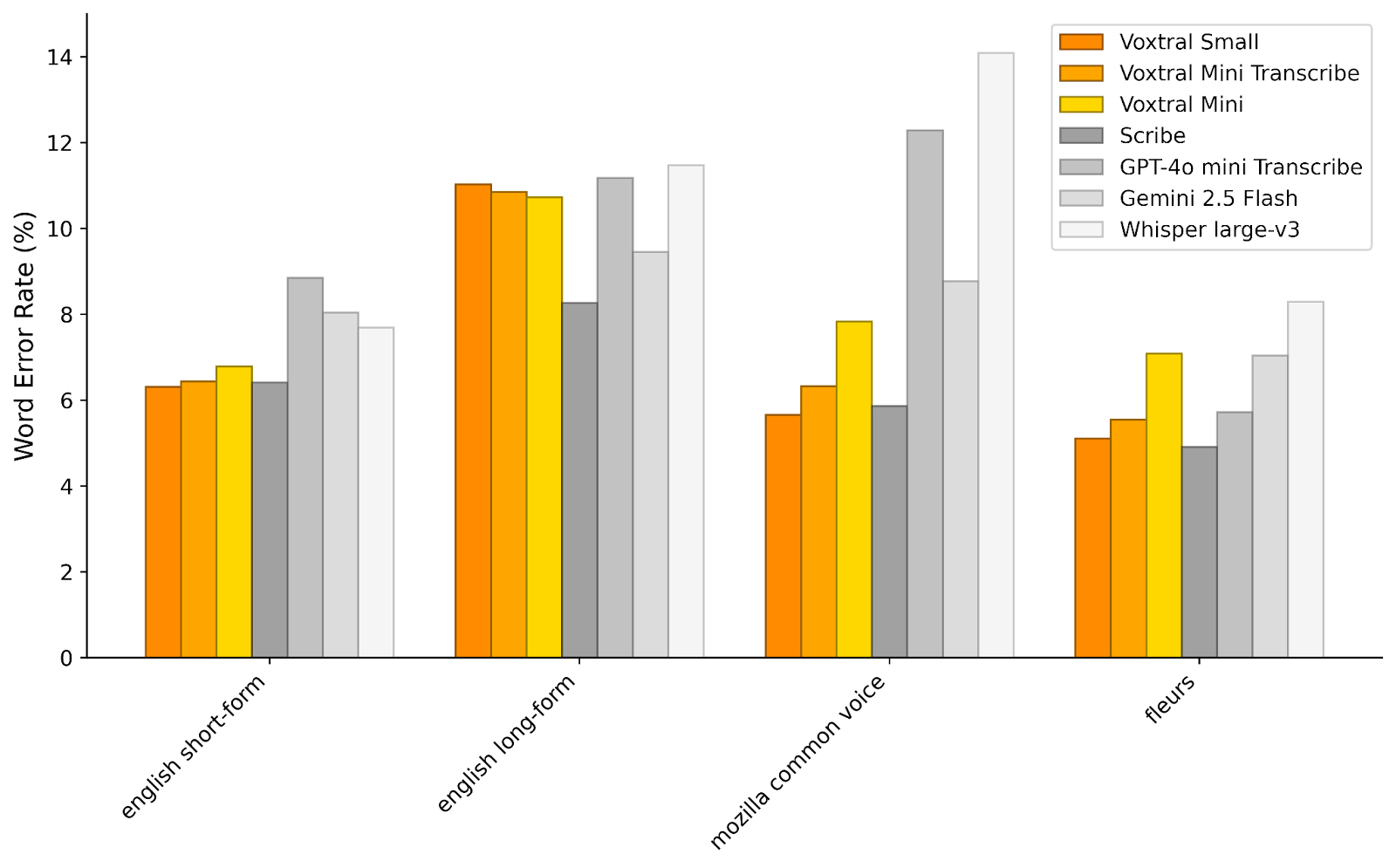
Model podporuje automatické rozpoznání jazyka a dosahuje špičkových výsledků v angličtině, španělštině, francouzštině, portugalštině, hindštině, němčině, holandštině, italštině a arabštině. Čeština v současné době bohužel podporovaná není. Podle oficiálních benchmarků překonává Voxtral Small model Whisper large-v3 ve všech testovaných úlohách včetně multijazyčního datasetu FLEURS.
Rozšířené funkce nad rámec transkripce
Na rozdíl od tradičních systémů automatického rozpoznávání řeči (ASR) nabízí Voxtral nativní sémantické porozumění bez nutnosti řetězení separátních modelů. Uživatelé mohou přímo z hlasu pokládat otázky o obsahu audia, generovat strukturované shrnutí nebo aktivovat funkce backendu prostřednictvím hlasových příkazů.
Funkce volání funkcí přímo z hlasu umožňuje přímé spouštění pracovních postupů nebo API volání na základě rozpoznaných hlasových příkazů uživatele. Tato schopnost převádí hlasové interakce na proveditelné systémové příkazy bez nutnosti mezikroků zpracování.
Model zachovává textové schopnosti svého základu Mistral Small 3.1, což z něj činí náhradu současných textových modelů s rozšířenými audio funkcemi. Tato vlastnost umožňuje používat Voxtral jako univerzální model pro textové i audio úlohy.
Srovnání výkonu a cen
Podle interních benchmarků společnosti Mistral AI dosahuje Voxtral Small srovnatelného výkonu s GPT-4o mini a Gemini 2.5 Flash napříč všemi testovanými úlohami. V oblasti překladu řeči dosahuje špičkových výsledků.
Pro krátké anglické audio (pod 30 sekund) vykazuje Voxtral nižší chybovost než Whisper large-v3. V multijazyčních scénářích včetně benchmarku Mozilla Common Voice překonává všechny testované konkurenty včetně ElevenLabs Scribe.
Cenová politika API začína na 0,001 USD za minutu zpracovaného audia, což představuje přibližně poloviční cenu oproti srovnatelným proprietárním řešením. Společnost také nabízí specializovaný endpoint API pouze pro transkripci s optimalizovanou cenovou efektivitou.
Dostupnost a integrace
Oba modely jsou dostupné ke stažení na platformě Hugging Face, což umožňuje lokální testování a nasazení. Vývojáři mohou model integrovat do svých aplikací prostřednictvím API Mistral AI s jednoduchou implementací.
Model bude postupně dostupný také v hlasovém režimu chatbota Le Chat od Mistral AI, který umožní nahrávání nebo přehrávání audia s následnou transkripci, odpověďmi na otázky nebo generováním shrnutí.
Podnikové funkce a budoucí vývoj
Mistral AI nabízí rozšířené možnosti pro podnikové zákazníky včetně privátního nasazení v produkčním měřítku, doménově specifického dolaďování a pokročilé kontextové podpory. Společnost pracuje na funkcích jako je identifikace mluvčích, detekce emocí, pokročilá diarizace a ještě delší kontextová okna.
V následujících měsících plánuje Mistral AI přidat segmentaci mluvčích, audio značky jako věk a emoce, časové značky na úrovni slov a rozpoznávání neřečového zvuku. Společnost také rozšiřuje svůj audio tým a hledá výzkumné pracovníky a inženýry.
Voxtral představuje pokrok v demokratizaci pokročilých hlasových technologií prostřednictvím otevřeného zdrojového kódu. Jeho kombinace vysokého výkonu, nízké ceny a otevřené licence může urychlit vývoj hlasových aplikací a služeb napříč různými odvětvími.
Mistral AI je francouzská společnost založená v roce 2023, která se zaměřuje na vývoj otevřených a efektivních modelů umělé inteligence. Společnost je známá svými modely Mistral 7B, Mixtral a dalšími, které konkurují proprietárním řešením při zachování otevřenosti.